 Welcome to the 2nd blog in Rucha Yantra’s series on Machine Learning (ML). In the previous blog, we took an overview of ML, explored the basic terminologies associated, and looked at the most trending applications of ML in the world. Going a bit deeper, we shall look at the different approaches to Machine Learning – the different ways it can work.
Welcome to the 2nd blog in Rucha Yantra’s series on Machine Learning (ML). In the previous blog, we took an overview of ML, explored the basic terminologies associated, and looked at the most trending applications of ML in the world. Going a bit deeper, we shall look at the different approaches to Machine Learning – the different ways it can work.
The basic functionality of ML is similar to how humans learn. Before an ML algorithm can analyze, judge, and finally act, it needs to be fed “learning” data for classification. Broadly, there are four different ways how this classification works. Let’s take a look!
1. Supervised learning: This is the most straightforward algorithm. Each data point is labeled and then fed to the machine. Manual classification is used for labeling the data. In other words, it is like telling the machine the standard answer to a problem at hand.
For example, if you wish to train a machine to predict whether a particular image is that of a dog or a cat, you would first provide 100 labeled pictures of dogs and cats to the machine. Based on the labels, the machine detects the characteristics of dogs and cats. Once a new image is fed, it predicts by comparing it to dogs and cats.
Apart from image detection, another common use of Supervised learning is in detection of spam emails. Email software are trained by classifying normal and spam emails manually, and then they become adept at predicting if an incoming email is spam. The email is sent to the designated folder based on the prediction.
As it consists of manual classification, it is the easiest for computers but the hardest for humans. However, the reliability of such algorithms is very high.
2. Unsupervised learning: In this type of algorithms, manual classification or labeling is not involved. Machine classifies the input data on its own by detecting its various characteristics. Using the same example as before, you would not classify the input images as dogs or cats. The machine must decide which of the 100 images provided are dogs or cats and classify them simultaneously. When an image is provided, it must refer to its classification for prediction.
A real world example would be how Amazon recommends “ Products you may also like” to you. The algorithm behind Amazon continuously studies our browsing and buying behaviour. It also keeps track of what items we put in our “cart”. It uncovers patterns in our activity and predicts which other items we are like to buy and makes the recommendations.
Such algorithms’ reliability is relatively low, and there is a higher chance of prediction errors.
3. Semi-supervised learning: As the 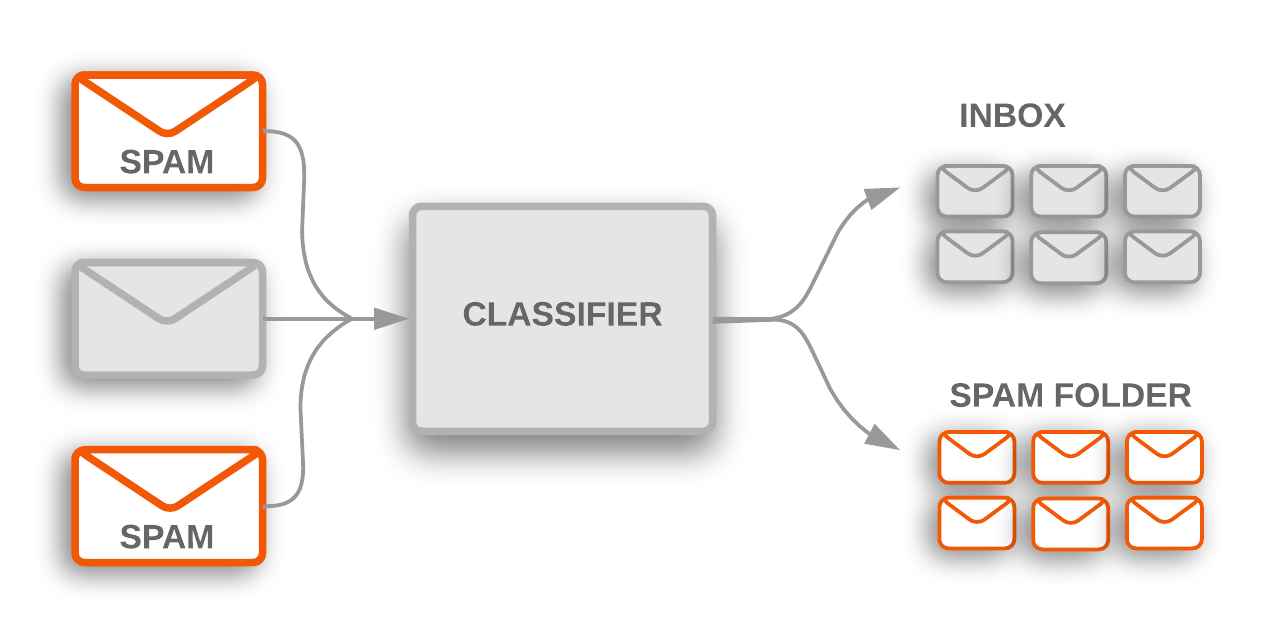 name suggests, this method falls somewhere between Supervised and Unsupervised learning. Unlike Supervised learning, wherein the entire input data is labeled, only a small proportion of the data provided is classified by humans. Computers must identify the features based on the labeled data and then classify the remaining accordingly.
name suggests, this method falls somewhere between Supervised and Unsupervised learning. Unlike Supervised learning, wherein the entire input data is labeled, only a small proportion of the data provided is classified by humans. Computers must identify the features based on the labeled data and then classify the remaining accordingly.
Hence, if there 100 photos of dogs and cats, only a small proportion of them, say 10 each, would be classified by humans. By learning the characteristics of these 20 photos, the machine would classify the remaining images. As the machine has already learned the basis for classification, the predicted results are relatively more accurate than Unsupervised learning.
Semi-supervised learning is increasingly being used in the medical field for predicting medical conditions based on scans. For example, a trained expert labels a small set of breast cancer scans which the algorithm uses to train itself. The “learning” can then be leveraged to predict, based on their scans, if a patient is suffering from breast cancer.
Such algorithms can make predictions more and more accurate and, thus, are the most commonly used.
4. Reinforcement learning: In this approach to ML, continuous human feedback is necessary. Humans provide no classification of data. However, when a machine classifies the input data on its own and moves to prediction, humans offer feedback on the classification to improve its results.
Thus, through 100 images of dogs and cats, if a machine predicts a dog image as a cat, a human would immediately provide feedback and correct the classification. The machine, then, amends the classification and improves its prediction. Although this is a relatively more time-consuming process, the final prediction becomes increasingly accurate over time. Reinforcement learning is often integrated with Unsupervised learning to improve the latter’s results. While reinforcement learning has not been used widely for real-world applications so far, leading tech companies are exploring its use through research.
Among the four approaches mentioned above, Supervised learning is the most accurate and the most expensive as it involves many manual efforts. Knowing these approaches to ML would help you understand better how ML works. So, the next time you stumble upon an ML application, try to identify which type of algorithm must be running behind it.
We hope that you found this blog interesting. Rucha Yantra shall keep writing about topics related to next-gen technologies to help you understand them in-depth. In the next blog, we shall try to understand how ML is helping improve manufacturing. Stay tuned to our Knowledge Corner for further blogs!


